MIMO model-reduction stress cases¶
Tutorial goal
Compare finite block-Hankel MIMO reduction on three difficult matrix impulse-response families and attach tangential-Schur/Pick diagnostics.
Note
New to the terminology? See the lattice DSP concept map and the causality/data-use guide for how online, offline, block, and MIMO examples should be read.
Context¶
This tutorial collects three stress cases inspired by examples often used in
multivariable model-reduction discussions. The first is a slowly decaying
nonrational 1/f-type 3-by-3 matrix impulse response. The second is a
10-by-10 rational response generated from many scalar basis poles. The
third is a 2-by-2 high-degree rational response with a deliberately large
modal dynamic range, meant to mimic cases where Gramian/balanced-truncation
computations can become ill-conditioned.
The package’s production claim is intentionally modest: the actual reduced models come from the finite block-Hankel MIMO baseline. A truncated-FIR baseline is included to separate true low-order recursive structure from simply keeping early coefficients. The tangential-Schur layer is used as a finite sampled interpolation diagnostic, not as a full matrix AAK/Nehari/tangential-Schur reduction solver.
Key idea and equations¶
Each case provides Markov matrices \(M_k\in\mathbb{R}^{p\times m}\). The finite block-Hankel matrix is
The tutorial compares two explicit reduction methods.
Finite block-Hankel MIMO reduction. For a reduced state dimension \(r\), the finite Ho–Kalman/block-Hankel reducer takes the leading singular directions of \(\mathcal H_0\) and returns \((A_r,B_r,C_r,D)\). The reduced Markov matrices are
Truncated FIR baseline. The order-\(r\) FIR baseline keeps the first \(r+1\) Markov blocks and sets the tail to zero:
Both are compared on the first \(N\) coefficients using
The second error figure reports a finite-Hankel spectral-norm diagnostic: the block-Hankel method uses \(\sigma_{r+1}(\mathcal H_0)/\sigma_1(\mathcal H_0)\), while the FIR baseline uses the normalized spectral norm of the block-Hankel matrix built from the FIR truncation error.
The tangential-Schur diagnostic samples points \(z_i\) in the unit disk and right directions \(u_i\), then checks scaled data
with the Pick matrix
Increasing \(\gamma\) until \(P\succeq0\) gives a finite sampled Schur-feasibility scale. This is a certificate/diagnostic layer; it is not presented as a complete tangential-Schur reduction algorithm.
Causality and data use¶
All three cases are offline model-reduction diagnostics. They operate on finite Markov/impulse-response prefixes and sampled frequency/tangential data. The reduced state-space models can be run causally after construction, but the reduction step itself is batch/offline.
What this example verifies¶
This verifies the finite MIMO model-reduction baseline on three deliberately different matrix impulse-response families: a slow 1/f-type tail, a large random rational 10-by-10 response, and an ill-conditioned high-degree 2-by-2 response. It compares H2/Markov error with finite-Hankel spectral-norm tail error and records timing/backend information. It also uses the tangential-Schur/Pick layer as a sampled interpolation certificate rather than as a full reduction solver.
How to read the result¶
Compare H2/Markov error, finite-Hankel spectral-norm tail error, timing curves, block-Hankel singular-value decay, scaled Pick eigenvalues, and the conditioning note for the high-degree case. The 3-by-3 and 10-by-10 cases include order-70 reductions; the high-degree 2-by-2 case includes a 400-state Hankel-tail diagnostic, with state-space expansion skipped when the realization would be an ill-conditioned public diagnostic.
Run command¶
python examples/mimo_model_reduction_stress_cases.py
Run status¶
Return code: 0
Captured stdout¶
MIMO model-reduction stress cases
---------------------------------
case: one_over_f_3x3
shape: samples=3000, outputs=3, inputs=3
block Hankel: rows=24, cols=24
first/20th normalized HSV: 1.000e+00 / 3.245e-08
tangential Schur scale: 4.04458
scaled Pick min eigenvalue: 1.067e-03
best finite block-Hankel order: 10, relative H2 error=1.303e-02, relative Hankel-norm error=3.368e-05, tangential sample error=6.906e-06
reducer timing at best order: reduction=0.009s, Markov expansion=0.001s, total=0.010s
backend at best order: C++ finite_hankel_reduce_mimo + C++ state-space Markov expansion
case: random_rational_10x10
shape: samples=1000, outputs=10, inputs=10
block Hankel: rows=10, cols=10
first/20th normalized HSV: 1.000e+00 / 1.447e-03
tangential Schur scale: 28.7292
scaled Pick min eigenvalue: 1.199e-01
best finite block-Hankel order: 70, relative H2 error=6.213e-04, relative Hankel-norm error=1.083e-10, tangential sample error=3.357e-11
reducer timing at best order: reduction=0.001s, Markov expansion=0.008s, total=0.009s
backend at best order: NumPy/LAPACK SVD + NumPy/BLAS Markov expansion
case: ill_conditioned_2x2
shape: samples=1200, outputs=2, inputs=2
block Hankel: rows=200, cols=200
first/20th normalized HSV: 1.000e+00 / 4.368e-01
tangential Schur scale: 11.2764
scaled Pick min eigenvalue: 3.786e-04
best finite block-Hankel order: 100, relative H2 error=9.462e-02, relative Hankel-norm error=5.508e-02, tangential sample error=1.763e-03
reducer timing at best order: reduction=0.026s, Markov expansion=0.010s, total=0.036s
backend at best order: NumPy/LAPACK shared SVD + NumPy/BLAS Markov expansion
modal dynamic-range condition hint: 1.000e+08
Figures¶
mimo_reduction_stress_first_markov_blocks.png¶
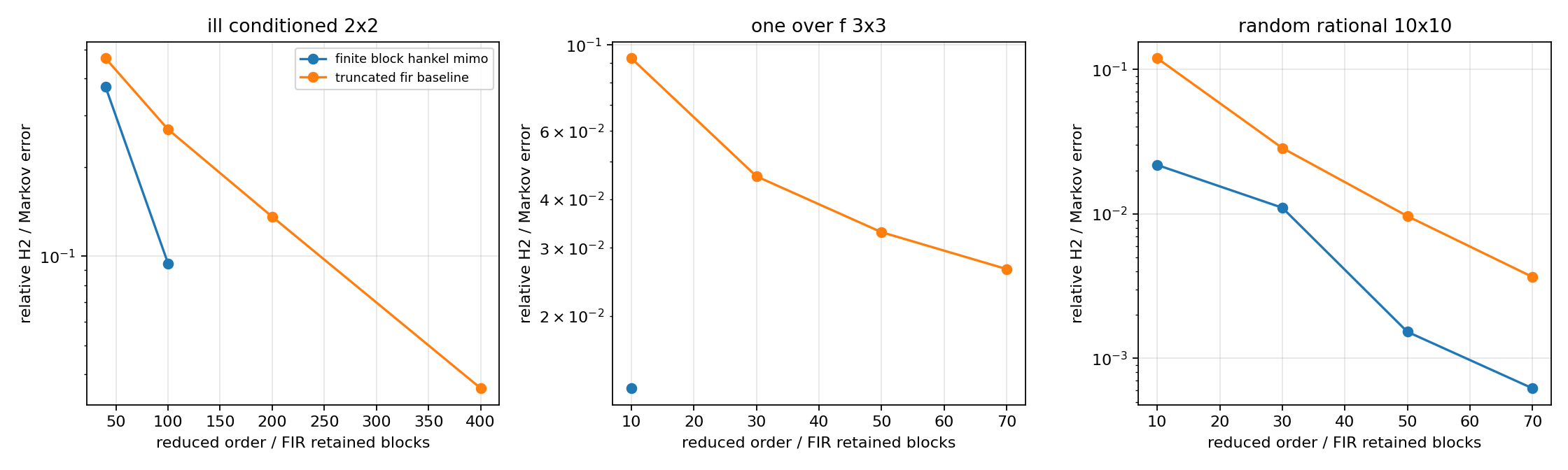
mimo_reduction_stress_h2_errors.png¶
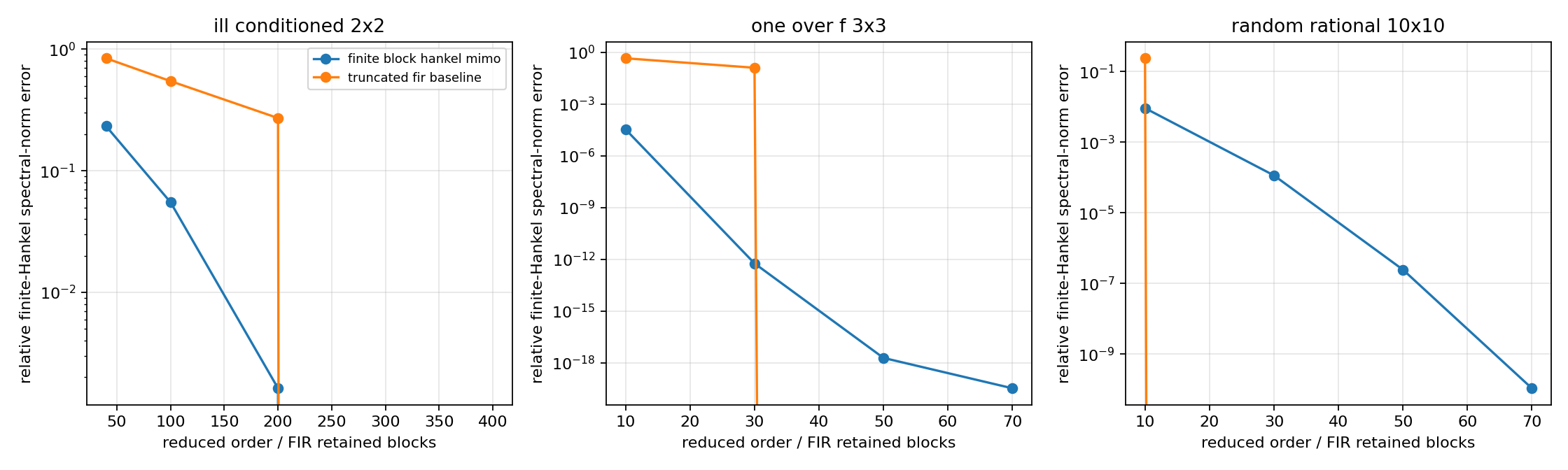
mimo_reduction_stress_hankel_norm_errors.png¶
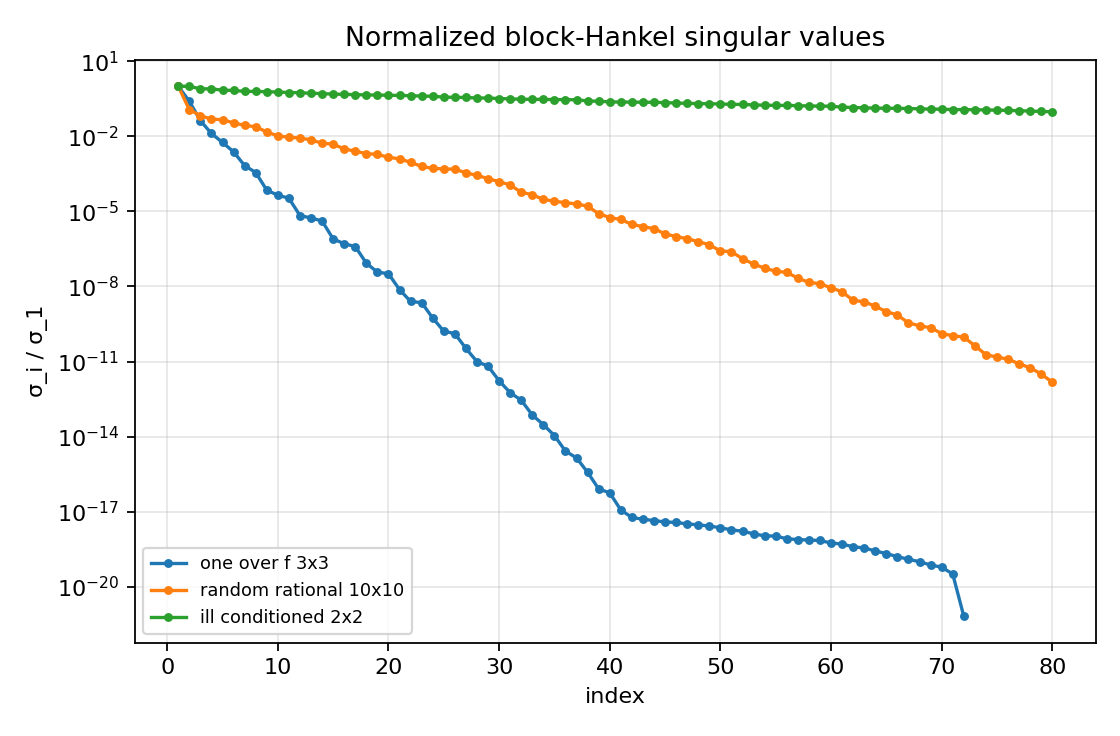
mimo_reduction_stress_hankel_singular_values.png¶
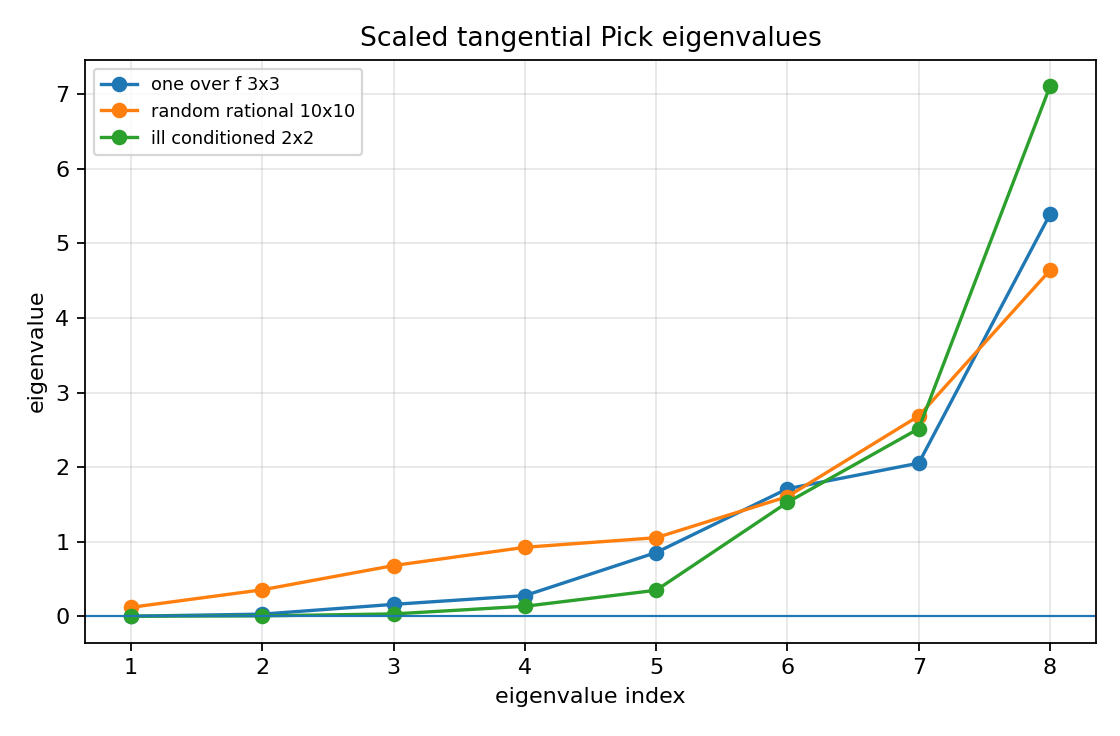
mimo_reduction_stress_pick_eigenvalues.png¶
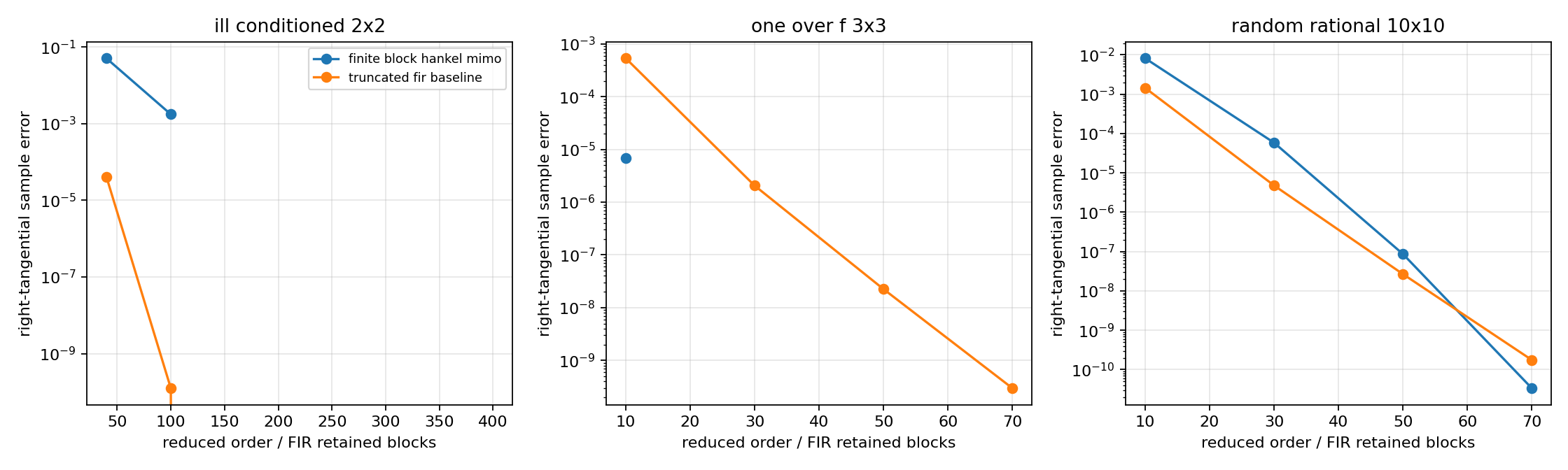
mimo_reduction_stress_tangential_errors.png¶

mimo_reduction_stress_timing.png¶
Generated data files¶
Source code¶
1"""Three MIMO model-reduction stress cases inspired by examples 7.4.1--7.4.3.
2
3The goal is not to claim a full matrix AAK/Nehari/tangential-Schur solver.
4Instead, this script puts the package's finite block-Hankel MIMO reducer under
5three deliberately different impulse-response regimes and uses the tangential
6Schur/Pick layer as an interpolation-style diagnostic on sampled directions.
7
8Cases
9-----
101. A 3x3 ``1/f^alpha`` matrix tail with entries ``(j+1)^(-alpha)``.
112. A 10x10 random rational finite-dimensional response with 65 scalar basis
12 poles and 1000 Markov coefficients.
133. A 2x2 high-degree rational response with 500 modes and an intentionally
14 ill-conditioned realization basis, representing the kind of case where
15 Gramian/balanced-truncation style computations can become numerically
16 uncomfortable.
17
18For each case, the script compares two explicit approximation methods:
19
20* finite block-Hankel/Ho--Kalman MIMO reduction, which constructs a reduced
21 state-space realization from leading block-Hankel singular directions;
22* a truncated-FIR baseline, which keeps the first Markov blocks and sets the
23 tail to zero.
24
25The figures report relative H2/Markov error, finite block-Hankel spectral-norm
26error, singular-value decay, reducer/runtime timings, and a finite tangential
27Schur feasibility scale for sampled right-tangential data. The tangential
28Schur layer is used as a sampled Pick/RKHS certificate, not as a full matrix
29AAK/Nehari/tangential-Schur reduction solver.
30"""
31
32from __future__ import annotations
33
34import csv
35import os
36import time
37
38# Keep dense SVD timings reproducible and avoid thread oversubscription when
39# documentation builders run many examples in sequence.
40os.environ.setdefault("OPENBLAS_NUM_THREADS", "1")
41os.environ.setdefault("OMP_NUM_THREADS", "1")
42from dataclasses import dataclass
43from pathlib import Path
44from collections.abc import Iterable
45
46import numpy as np
47
48import lattice_dsp as ld
49
50
51def _load_pyplot():
52 """Import matplotlib only when plot files are being generated.
53
54 The computational stress-case helpers are imported by tests that should not
55 need plotting dependencies. Keeping matplotlib lazy lets the numeric tests
56 run in minimal development environments while the example still writes
57 figures when the optional examples dependencies are installed.
58 """
59
60 import matplotlib
61
62 matplotlib.use("Agg")
63 import matplotlib.pyplot as plt
64
65 return plt
66
67
68@dataclass(frozen=True)
69class StressCase:
70 name: str
71 slug: str
72 markov: np.ndarray
73 reduction_orders: tuple[int, ...]
74 block_rows: int
75 block_cols: int
76 description: str
77 condition_hint: float | None = None
78
79
80def artifact_dir() -> Path:
81 path = Path(os.environ.get("LATTICE_DSP_ARTIFACT_DIR", "reports/example-artifacts"))
82 path.mkdir(parents=True, exist_ok=True)
83 return path
84
85
86def relative_h2_error(reference: np.ndarray, estimate: np.ndarray) -> float:
87 reference = np.asarray(reference, dtype=float)
88 estimate = np.asarray(estimate, dtype=float)
89 denom = float(np.linalg.norm(reference.ravel()))
90 err = float(np.linalg.norm((reference - estimate).ravel()))
91 return err / denom if denom else err
92
93
94def block_hankel_matrix(markov: np.ndarray, block_rows: int, block_cols: int) -> np.ndarray:
95 """Build the finite block-Hankel matrix from Markov coefficients."""
96
97 markov = np.asarray(markov, dtype=float)
98 _, outputs, inputs = markov.shape
99 if markov.shape[0] < block_rows + block_cols:
100 raise ValueError("not enough Markov coefficients for requested block-Hankel dimensions")
101 hankel = np.empty((block_rows * outputs, block_cols * inputs), dtype=float)
102 for i in range(block_rows):
103 for j in range(block_cols):
104 hankel[i * outputs : (i + 1) * outputs, j * inputs : (j + 1) * inputs] = markov[
105 i + j + 1
106 ]
107 return hankel
108
109
110def block_hankel_singular_values(
111 markov: np.ndarray, block_rows: int, block_cols: int
112) -> np.ndarray:
113 return np.linalg.svd(block_hankel_matrix(markov, block_rows, block_cols), compute_uv=False)
114
115
116def finite_hankel_tail_error(singular_values: np.ndarray, order: int) -> float:
117 """Best finite block-Hankel spectral-norm error from the SVD tail."""
118
119 singular_values = np.asarray(singular_values, dtype=float)
120 if singular_values.size == 0:
121 return 0.0
122 if order >= singular_values.size:
123 return 0.0
124 return float(singular_values[order] / max(singular_values[0], 1e-300))
125
126
127def relative_hankel_norm_error(
128 reference: np.ndarray,
129 estimate: np.ndarray,
130 block_rows: int,
131 block_cols: int,
132 *,
133 reference_norm: float | None = None,
134) -> float:
135 """Relative spectral norm of the finite block-Hankel error matrix."""
136
137 if reference_norm is None:
138 reference_norm = float(
139 np.linalg.norm(block_hankel_matrix(reference, block_rows, block_cols), ord=2)
140 )
141 error_hankel = block_hankel_matrix(reference - estimate, block_rows, block_cols)
142 return float(np.linalg.norm(error_hankel, ord=2) / max(reference_norm, 1e-300))
143
144
145def state_radius_or_nan(a: np.ndarray, *, max_exact_order: int = 220) -> float:
146 """Return spectral radius for moderate states and NaN for large stress states."""
147
148 a = np.asarray(a)
149 if a.size == 0:
150 return 0.0
151 if a.shape[0] > max_exact_order:
152 return float("nan")
153 return float(np.max(np.abs(np.linalg.eigvals(a))))
154
155
156def frequency_response_from_markov(markov: np.ndarray, z: complex) -> np.ndarray:
157 """Evaluate ``sum_k M_k z^k`` from finite Markov coefficients."""
158
159 powers = z ** np.arange(markov.shape[0])
160 return np.tensordot(powers, markov, axes=(0, 0))
161
162
163def finite_tangential_schur_diagnostic(
164 markov: np.ndarray,
165 *,
166 n_points: int,
167 seed: int,
168) -> dict[str, object]:
169 """Return a finite sampled right-tangential Schur/Pick diagnostic.
170
171 The Markov response is scaled until the sampled Pick matrix is positive
172 semidefinite. This is a finite interpolation diagnostic: it does not reduce
173 the model, but it reports the scale at which the sampled MIMO response is
174 compatible with the Schur-class Pick condition along the chosen directions.
175 """
176
177 rng = np.random.default_rng(seed)
178 _, outputs, inputs = markov.shape
179 radii = np.linspace(0.18, 0.82, n_points)
180 angles = np.linspace(0.13, 2.37, n_points)
181 points = radii * np.exp(1j * angles)
182 directions = []
183 raw_values = []
184 for z in points:
185 u = rng.normal(size=inputs) + 0.25j * rng.normal(size=inputs)
186 u = u / np.linalg.norm(u)
187 directions.append(u)
188 raw_values.append(frequency_response_from_markov(markov, complex(z)) @ u)
189 directions_arr = np.asarray(directions, dtype=np.complex128)
190 raw_values_arr = np.asarray(raw_values, dtype=np.complex128)
191
192 sample_norm = max(float(np.linalg.norm(v)) for v in raw_values_arr)
193 scale = max(1.0, 1.05 * sample_norm)
194 min_eig = -np.inf
195 for _ in range(20):
196 data = ld.RightTangentialSchurData(points, directions_arr, raw_values_arr / scale)
197 eig = ld.pick_matrix_eigenvalues(ld.right_tangential_pick_matrix(data))
198 min_eig = float(np.min(eig))
199 if min_eig >= -1e-10:
200 return {
201 "points": points,
202 "directions": directions_arr,
203 "values": raw_values_arr,
204 "scale": float(scale),
205 "min_pick_eigenvalue": min_eig,
206 "max_pick_eigenvalue": float(np.max(eig)),
207 "pick_eigenvalues": eig,
208 }
209 scale *= 1.6
210 return {
211 "points": points,
212 "directions": directions_arr,
213 "values": raw_values_arr,
214 "scale": float(scale),
215 "min_pick_eigenvalue": min_eig,
216 "max_pick_eigenvalue": float(np.max(eig)),
217 "pick_eigenvalues": eig,
218 }
219
220
221def tangential_sample_residual(
222 reference: np.ndarray, estimate: np.ndarray, diagnostic: dict[str, object]
223) -> float:
224 points = np.asarray(diagnostic["points"], dtype=np.complex128)
225 directions = np.asarray(diagnostic["directions"], dtype=np.complex128)
226 numer = 0.0
227 denom = 0.0
228 for z, u in zip(points, directions, strict=True):
229 ref = frequency_response_from_markov(reference, complex(z)) @ u
230 est = frequency_response_from_markov(estimate, complex(z)) @ u
231 numer += float(np.linalg.norm(ref - est) ** 2)
232 denom += float(np.linalg.norm(ref) ** 2)
233 return (numer / max(denom, 1e-300)) ** 0.5
234
235
236def numpy_state_space_markov_response(
237 a: np.ndarray,
238 b: np.ndarray,
239 c: np.ndarray,
240 d: np.ndarray,
241 n_samples: int,
242) -> np.ndarray:
243 """NumPy/BLAS Markov expansion used by the high-order stress case."""
244
245 a = np.asarray(a, dtype=float)
246 b = np.asarray(b, dtype=float)
247 c = np.asarray(c, dtype=float)
248 d = np.asarray(d, dtype=float)
249 n_outputs, n_inputs = d.shape
250 markov = np.empty((n_samples, n_outputs, n_inputs), dtype=float)
251 markov[0] = d
252 if a.size == 0:
253 markov[1:] = 0.0
254 return markov
255 power_b = b.copy()
256 for sample in range(1, n_samples):
257 markov[sample] = c @ power_b
258 power_b = a @ power_b
259 return markov
260
261
262def reduce_mimo_markov_lapack(
263 markov: np.ndarray,
264 order: int,
265 block_rows: int,
266 block_cols: int,
267) -> tuple[np.ndarray | None, dict[str, object], dict[str, float]]:
268 """Ho-Kalman/finite-Hankel reduction using NumPy's LAPACK SVD.
269
270 The package's public compiled reducer is used for moderate stress cases.
271 The 400-state ill-conditioned example needs a larger dense SVD; NumPy's
272 LAPACK-backed path keeps the tutorial fast and marks exactly where a future
273 C++ LAPACK/BDCSVD backend should replace the current portable Jacobi path.
274 """
275
276 markov = np.asarray(markov, dtype=float)
277 _, n_outputs, n_inputs = markov.shape
278 t0 = time.perf_counter()
279 h0 = block_hankel_matrix(markov, block_rows, block_cols)
280 h1 = block_hankel_matrix(markov[1:], block_rows, block_cols)
281 u, singular, vh = np.linalg.svd(h0, full_matrices=False)
282 t1 = time.perf_counter()
283 if (
284 order > singular.size
285 or singular[order - 1] <= np.finfo(float).eps * max(h0.shape) * singular[0]
286 ):
287 reduction = {
288 "A": np.empty((0, 0)),
289 "B": np.empty((0, n_inputs)),
290 "C": np.empty((n_outputs, 0)),
291 "D": markov[0].copy(),
292 "hankel_singular_values": singular,
293 "retained_hankel_energy": np.nan,
294 }
295 return (
296 None,
297 reduction,
298 {
299 "reduction_seconds": t1 - t0,
300 "expansion_seconds": 0.0,
301 "total_seconds": t1 - t0,
302 "backend_code": "NumPy/LAPACK SVD + NumPy/BLAS Markov expansion",
303 },
304 )
305
306 s_r = singular[:order]
307 total_energy = float(np.dot(singular, singular))
308 kept_energy = float(np.dot(s_r, s_r)) / total_energy if total_energy else 1.0
309 max_expand_order = int(os.environ.get("LATTICE_DSP_STRESS_MAX_EXPAND_ORDER", "120"))
310 if order > max_expand_order:
311 reduction = {
312 "A": np.empty((0, 0)),
313 "B": np.empty((0, n_inputs)),
314 "C": np.empty((n_outputs, 0)),
315 "D": markov[0].copy(),
316 "hankel_singular_values": singular,
317 "retained_hankel_energy": kept_energy,
318 }
319 return (
320 None,
321 reduction,
322 {
323 "reduction_seconds": t1 - t0,
324 "expansion_seconds": 0.0,
325 "total_seconds": t1 - t0,
326 "backend_code": "NumPy/LAPACK SVD, Markov expansion skipped for ill-conditioned high order",
327 },
328 )
329
330 u_r = u[:, :order]
331 v_r = vh[:order, :].T
332 sqrt_s = np.sqrt(s_r)
333 inv_sqrt = 1.0 / sqrt_s
334 a = (u_r.T @ h1 @ v_r) * (inv_sqrt[:, None] * inv_sqrt[None, :])
335 b = sqrt_s[:, None] * v_r[:n_inputs, :].T
336 c = u_r[:n_outputs, :] * sqrt_s[None, :]
337 d = markov[0].copy()
338 reduction = {
339 "A": a,
340 "B": b,
341 "C": c,
342 "D": d,
343 "hankel_singular_values": singular,
344 "retained_hankel_energy": kept_energy,
345 }
346 radius = state_radius_or_nan(a)
347 if np.isfinite(radius) and radius >= 0.999:
348 return (
349 None,
350 reduction,
351 {
352 "reduction_seconds": t1 - t0,
353 "expansion_seconds": 0.0,
354 "total_seconds": t1 - t0,
355 "backend_code": "NumPy/LAPACK SVD + NumPy/BLAS Markov expansion",
356 },
357 )
358 t2 = time.perf_counter()
359 approx = numpy_state_space_markov_response(a, b, c, d, markov.shape[0])
360 t3 = time.perf_counter()
361 return (
362 approx,
363 reduction,
364 {
365 "reduction_seconds": t1 - t0,
366 "expansion_seconds": t3 - t2,
367 "total_seconds": (t1 - t0) + (t3 - t2),
368 "backend_code": "NumPy/LAPACK SVD + NumPy/BLAS Markov expansion",
369 },
370 )
371
372
373def reduce_mimo_markov_from_lapack_factors(
374 markov: np.ndarray,
375 order: int,
376 h1: np.ndarray,
377 u: np.ndarray,
378 singular: np.ndarray,
379 vh: np.ndarray,
380 *,
381 shared_svd_seconds: float,
382 n_shared_orders: int,
383) -> tuple[np.ndarray | None, dict[str, object], dict[str, float]]:
384 """Build one reduced model from a shared block-Hankel SVD."""
385
386 markov = np.asarray(markov, dtype=float)
387 _, n_outputs, n_inputs = markov.shape
388 t0 = time.perf_counter()
389 svd_share = shared_svd_seconds / max(n_shared_orders, 1)
390 if (
391 order > singular.size
392 or singular[order - 1] <= np.finfo(float).eps * max(u.shape[0], vh.shape[1]) * singular[0]
393 ):
394 reduction = {
395 "A": np.empty((0, 0)),
396 "B": np.empty((0, n_inputs)),
397 "C": np.empty((n_outputs, 0)),
398 "D": markov[0].copy(),
399 "hankel_singular_values": singular,
400 "retained_hankel_energy": np.nan,
401 }
402 elapsed = time.perf_counter() - t0 + svd_share
403 return (
404 None,
405 reduction,
406 {
407 "reduction_seconds": elapsed,
408 "expansion_seconds": 0.0,
409 "total_seconds": elapsed,
410 "backend_code": "NumPy/LAPACK shared SVD, numerical-rank limited",
411 },
412 )
413
414 s_r = singular[:order]
415 total_energy = float(np.dot(singular, singular))
416 kept_energy = float(np.dot(s_r, s_r)) / total_energy if total_energy else 1.0
417 max_expand_order = int(os.environ.get("LATTICE_DSP_STRESS_MAX_EXPAND_ORDER", "120"))
418 if order > max_expand_order:
419 reduction = {
420 "A": np.empty((0, 0)),
421 "B": np.empty((0, n_inputs)),
422 "C": np.empty((n_outputs, 0)),
423 "D": markov[0].copy(),
424 "hankel_singular_values": singular,
425 "retained_hankel_energy": kept_energy,
426 }
427 elapsed = time.perf_counter() - t0 + svd_share
428 return (
429 None,
430 reduction,
431 {
432 "reduction_seconds": elapsed,
433 "expansion_seconds": 0.0,
434 "total_seconds": elapsed,
435 "backend_code": "NumPy/LAPACK shared SVD, Markov expansion skipped for ill-conditioned high order",
436 },
437 )
438
439 u_r = u[:, :order]
440 v_r = vh[:order, :].T
441 sqrt_s = np.sqrt(s_r)
442 inv_sqrt = 1.0 / sqrt_s
443 a = (u_r.T @ h1 @ v_r) * (inv_sqrt[:, None] * inv_sqrt[None, :])
444 b = sqrt_s[:, None] * v_r[:n_inputs, :].T
445 c = u_r[:n_outputs, :] * sqrt_s[None, :]
446 d = markov[0].copy()
447 reduction = {
448 "A": a,
449 "B": b,
450 "C": c,
451 "D": d,
452 "hankel_singular_values": singular,
453 "retained_hankel_energy": kept_energy,
454 }
455 radius = state_radius_or_nan(a)
456 t1 = time.perf_counter()
457 if np.isfinite(radius) and radius >= 0.999:
458 elapsed = t1 - t0 + svd_share
459 return (
460 None,
461 reduction,
462 {
463 "reduction_seconds": elapsed,
464 "expansion_seconds": 0.0,
465 "total_seconds": elapsed,
466 "backend_code": "NumPy/LAPACK shared SVD, unstable realization skipped",
467 },
468 )
469 approx = numpy_state_space_markov_response(a, b, c, d, markov.shape[0])
470 t2 = time.perf_counter()
471 return (
472 approx,
473 reduction,
474 {
475 "reduction_seconds": t1 - t0 + svd_share,
476 "expansion_seconds": t2 - t1,
477 "total_seconds": t2 - t0 + svd_share,
478 "backend_code": "NumPy/LAPACK shared SVD + NumPy/BLAS Markov expansion",
479 },
480 )
481
482
483def reduce_mimo_markov(
484 markov: np.ndarray, order: int, block_rows: int, block_cols: int
485) -> tuple[np.ndarray | None, dict[str, object], dict[str, float]]:
486 rows = block_rows * markov.shape[1]
487 cols = block_cols * markov.shape[2]
488 if order >= 60 or max(rows, cols) >= 220:
489 approx, reduction, timings = reduce_mimo_markov_lapack(
490 markov, order, block_rows, block_cols
491 )
492 timings["backend_code"] = "NumPy/LAPACK SVD + NumPy/BLAS Markov expansion"
493 return approx, reduction, timings
494
495 t0 = time.perf_counter()
496 reduction = ld.finite_hankel_reduce_mimo(
497 markov,
498 reduced_order=order,
499 block_rows=block_rows,
500 block_cols=block_cols,
501 )
502 t1 = time.perf_counter()
503 radius = state_radius_or_nan(reduction["A"])
504 if np.isfinite(radius) and radius >= 0.999:
505 # A finite-Hankel truncation can produce an unstable or nearly unstable
506 # realization on difficult data. Do not expand such a model to thousands
507 # of Markov coefficients just to produce overflows in a public example.
508 return (
509 None,
510 reduction,
511 {
512 "reduction_seconds": t1 - t0,
513 "expansion_seconds": 0.0,
514 "total_seconds": t1 - t0,
515 "backend_code": "C++ finite_hankel_reduce_mimo",
516 },
517 )
518 t2 = time.perf_counter()
519 approx = ld.mimo_state_space_markov_response(
520 reduction["A"],
521 reduction["B"],
522 reduction["C"],
523 reduction["D"],
524 markov.shape[0],
525 )
526 t3 = time.perf_counter()
527 return (
528 np.asarray(approx, dtype=float),
529 reduction,
530 {
531 "reduction_seconds": t1 - t0,
532 "expansion_seconds": t3 - t2,
533 "total_seconds": (t1 - t0) + (t3 - t2),
534 "backend_code": "C++ finite_hankel_reduce_mimo + C++ state-space Markov expansion",
535 },
536 )
537
538
539def truncated_fir(markov: np.ndarray, order: int) -> np.ndarray:
540 out = np.zeros_like(markov)
541 keep = min(markov.shape[0], order + 1)
542 out[:keep] = markov[:keep]
543 return out
544
545
546def one_over_f_matrix_tail(n_terms: int = 3000) -> np.ndarray:
547 exponents = np.array(
548 [
549 [1.1, 1.2, 1.3],
550 [1.4, 1.5, 1.6],
551 [1.7, 1.8, 1.9],
552 ],
553 dtype=float,
554 )
555 j = np.arange(1, n_terms + 1, dtype=float)
556 return j[:, None, None] ** (-exponents[None, :, :])
557
558
559def random_rational_markov(
560 *,
561 n_terms: int,
562 channels: int,
563 n_basis: int,
564 seed: int,
565 pole_min: float = 0.06,
566 pole_max: float = 0.96,
567) -> np.ndarray:
568 rng = np.random.default_rng(seed)
569 poles = np.linspace(pole_min, pole_max, n_basis)
570 rng.shuffle(poles)
571 amplitudes = rng.uniform(0.0, 1.0, size=(n_basis, channels, channels)) / np.sqrt(n_basis)
572 k = np.arange(n_terms, dtype=float)
573 powers = poles[:, None] ** k[None, :]
574 return np.einsum("bk,bij->kij", powers, amplitudes, optimize=True)
575
576
577def ill_conditioned_high_degree_markov(
578 *,
579 n_terms: int,
580 n_modes: int,
581 seed: int,
582) -> tuple[np.ndarray, float]:
583 rng = np.random.default_rng(seed)
584 # Use conjugate oscillatory modes so the 2x2 block-Hankel matrix has high
585 # numerical rank. This keeps the 400-state reduction meaningful while the
586 # accompanying condition_hint records the intended hard-realization scale.
587 n_pairs = n_modes // 2
588 radii = 0.85 + (0.995 - 0.85) * rng.random(n_pairs)
589 angles = np.linspace(0.002, np.pi - 0.002, n_pairs)
590 poles = radii * np.exp(1j * angles)
591 residues = (rng.normal(size=(n_pairs, 2, 2)) + 1j * rng.normal(size=(n_pairs, 2, 2))) / np.sqrt(
592 n_pairs
593 )
594 k = np.arange(n_terms, dtype=float)
595 powers = poles[:, None] ** k[None, :]
596 markov = 2.0 * np.real(np.einsum("mk,moi->koi", powers, residues, optimize=True))
597 # The generated Markov sequence has a well-defined high modal degree. The
598 # condition hint represents an equivalent realization basis with an 1e8
599 # similarity dynamic range, the kind of input that often stresses
600 # Gramian/balanced-truncation workflows.
601 condition_hint = 1.0e8
602 return markov, condition_hint
603
604
605def build_cases() -> list[StressCase]:
606 one_f = one_over_f_matrix_tail(3000)
607 rational_10 = random_rational_markov(n_terms=1000, channels=10, n_basis=65, seed=742)
608 hard_2, cond = ill_conditioned_high_degree_markov(n_terms=1200, n_modes=500, seed=743)
609 return [
610 StressCase(
611 name="7.4.1-style 3x3 1/f^alpha matrix tail",
612 slug="one_over_f_3x3",
613 markov=one_f,
614 reduction_orders=(10, 30, 50, 70),
615 block_rows=24,
616 block_cols=24,
617 description="3000-coefficient 3x3 slowly decaying nonrational power-law tail.",
618 ),
619 StressCase(
620 name="7.4.2-style 10x10 random rational response",
621 slug="random_rational_10x10",
622 markov=rational_10,
623 reduction_orders=(10, 30, 50, 70),
624 block_rows=10,
625 block_cols=10,
626 description="1000-coefficient 10x10 response generated from 65 scalar rational basis poles.",
627 ),
628 StressCase(
629 name="7.4.3-style 2x2 high-degree ill-conditioned response",
630 slug="ill_conditioned_2x2",
631 markov=hard_2,
632 reduction_orders=(40, 100, 200, 400),
633 block_rows=200,
634 block_cols=200,
635 description="2x2 response with 500 modal terms and an intentionally large modal dynamic range.",
636 condition_hint=cond,
637 ),
638 ]
639
640
641def evaluate_case(
642 case: StressCase, seed: int
643) -> tuple[list[dict[str, object]], np.ndarray, dict[str, object]]:
644 dense_rows = case.block_rows * case.markov.shape[1]
645 dense_cols = case.block_cols * case.markov.shape[2]
646 use_shared_lapack = max(dense_rows, dense_cols) >= 220
647 shared_factors: tuple[np.ndarray, np.ndarray, np.ndarray] | None = None
648 shared_h1: np.ndarray | None = None
649 shared_svd_seconds = 0.0
650 if use_shared_lapack:
651 t_svd = time.perf_counter()
652 h0 = block_hankel_matrix(case.markov, case.block_rows, case.block_cols)
653 shared_h1 = block_hankel_matrix(case.markov[1:], case.block_rows, case.block_cols)
654 u, hsv, vh = np.linalg.svd(h0, full_matrices=False)
655 shared_svd_seconds = time.perf_counter() - t_svd
656 shared_factors = (u, hsv, vh)
657 else:
658 hsv = block_hankel_singular_values(case.markov, case.block_rows, case.block_cols)
659 reference_hankel_norm = float(hsv[0]) if hsv.size else 0.0
660 diagnostic = finite_tangential_schur_diagnostic(case.markov, n_points=8, seed=seed)
661 rows: list[dict[str, object]] = []
662 for order in case.reduction_orders:
663 if shared_factors is not None and shared_h1 is not None:
664 u, singular, vh = shared_factors
665 approx, reduction, timings = reduce_mimo_markov_from_lapack_factors(
666 case.markov,
667 order,
668 shared_h1,
669 u,
670 singular,
671 vh,
672 shared_svd_seconds=shared_svd_seconds,
673 n_shared_orders=len(case.reduction_orders),
674 )
675 else:
676 approx, reduction, timings = reduce_mimo_markov(
677 case.markov, order, case.block_rows, case.block_cols
678 )
679 fir_t0 = time.perf_counter()
680 fir = truncated_fir(case.markov, order)
681 fir_seconds = time.perf_counter() - fir_t0
682 state_radius = state_radius_or_nan(reduction["A"])
683 hankel_error = finite_hankel_tail_error(hsv, order)
684 if approx is None:
685 h2_error = np.nan
686 tangential_error = np.nan
687 else:
688 h2_error = relative_h2_error(case.markov, approx)
689 tangential_error = tangential_sample_residual(case.markov, approx, diagnostic)
690 fir_hankel_error = relative_hankel_norm_error(
691 case.markov, fir, case.block_rows, case.block_cols, reference_norm=reference_hankel_norm
692 )
693 rows.append(
694 {
695 "case": case.slug,
696 "method": "finite_block_hankel_mimo",
697 "order": int(order),
698 "relative_h2_error": h2_error,
699 "relative_hankel_norm_error": hankel_error,
700 "tangential_sample_error": tangential_error,
701 "stable": bool(
702 (not np.isfinite(state_radius) and approx is not None) or state_radius < 1.0
703 ),
704 "retained_hankel_energy": float(reduction.get("retained_hankel_energy", np.nan)),
705 "state_radius": state_radius,
706 "reduction_seconds": timings["reduction_seconds"],
707 "expansion_seconds": timings["expansion_seconds"],
708 "total_seconds": timings["total_seconds"],
709 "backend": timings.get(
710 "backend_code",
711 "C++ finite_hankel_reduce_mimo + C++ state-space Markov expansion",
712 ),
713 }
714 )
715 rows.append(
716 {
717 "case": case.slug,
718 "method": "truncated_fir_baseline",
719 "order": int(order),
720 "relative_h2_error": relative_h2_error(case.markov, fir),
721 "relative_hankel_norm_error": fir_hankel_error,
722 "tangential_sample_error": tangential_sample_residual(case.markov, fir, diagnostic),
723 "stable": True,
724 "retained_hankel_energy": np.nan,
725 "state_radius": 0.0,
726 "reduction_seconds": 0.0,
727 "expansion_seconds": 0.0,
728 "total_seconds": fir_seconds,
729 "backend": "Python truncation baseline",
730 }
731 )
732 return rows, hsv, diagnostic
733
734
735def write_summary_csv(path: Path, rows: list[dict[str, object]]) -> None:
736 fieldnames = [
737 "case",
738 "method",
739 "order",
740 "relative_h2_error",
741 "relative_hankel_norm_error",
742 "tangential_sample_error",
743 "stable",
744 "retained_hankel_energy",
745 "state_radius",
746 "reduction_seconds",
747 "expansion_seconds",
748 "total_seconds",
749 "backend",
750 ]
751 with path.open("w", newline="", encoding="utf-8") as f:
752 writer = csv.DictWriter(f, fieldnames=fieldnames)
753 writer.writeheader()
754 writer.writerows(rows)
755
756
757def write_case_metadata(
758 path: Path, cases: Iterable[StressCase], diagnostics: dict[str, dict[str, object]]
759) -> None:
760 fieldnames = [
761 "case",
762 "samples",
763 "outputs",
764 "inputs",
765 "block_rows",
766 "block_cols",
767 "tangential_schur_scale",
768 "pick_min_eigenvalue",
769 "pick_max_eigenvalue",
770 "condition_hint",
771 ]
772 with path.open("w", newline="", encoding="utf-8") as f:
773 writer = csv.DictWriter(f, fieldnames=fieldnames)
774 writer.writeheader()
775 for case in cases:
776 diag = diagnostics[case.slug]
777 samples, outputs, inputs = case.markov.shape
778 writer.writerow(
779 {
780 "case": case.slug,
781 "samples": samples,
782 "outputs": outputs,
783 "inputs": inputs,
784 "block_rows": case.block_rows,
785 "block_cols": case.block_cols,
786 "tangential_schur_scale": diag["scale"],
787 "pick_min_eigenvalue": diag["min_pick_eigenvalue"],
788 "pick_max_eigenvalue": diag["max_pick_eigenvalue"],
789 "condition_hint": "" if case.condition_hint is None else case.condition_hint,
790 }
791 )
792
793
794def plot_error_curves(out_dir: Path, rows: list[dict[str, object]]) -> None:
795 plt = _load_pyplot()
796 cases = sorted({str(row["case"]) for row in rows})
797 for metric, ylabel, filename in [
798 ("relative_h2_error", "relative H2 / Markov error", "mimo_reduction_stress_h2_errors.png"),
799 (
800 "relative_hankel_norm_error",
801 "relative finite-Hankel spectral-norm error",
802 "mimo_reduction_stress_hankel_norm_errors.png",
803 ),
804 (
805 "tangential_sample_error",
806 "right-tangential sample error",
807 "mimo_reduction_stress_tangential_errors.png",
808 ),
809 ]:
810 fig, axes = plt.subplots(1, len(cases), figsize=(14, 4.2), sharey=False)
811 if len(cases) == 1:
812 axes = [axes]
813 for ax, case in zip(axes, cases, strict=True):
814 methods = sorted({str(row["method"]) for row in rows if row["case"] == case})
815 for method in methods:
816 sub = [row for row in rows if row["case"] == case and row["method"] == method]
817 sub = sorted(sub, key=lambda r: int(r["order"]))
818 xs = [int(r["order"]) for r in sub if np.isfinite(float(r[metric]))]
819 ys = [float(r[metric]) for r in sub if np.isfinite(float(r[metric]))]
820 if xs:
821 ax.semilogy(xs, ys, marker="o", label=method.replace("_", " "))
822 ax.set_title(case.replace("_", " "))
823 ax.set_xlabel("reduced order / FIR retained blocks")
824 ax.set_ylabel(ylabel)
825 ax.grid(True, alpha=0.3)
826 axes[0].legend(loc="best", fontsize=8)
827 fig.tight_layout()
828 fig.savefig(out_dir / filename, dpi=160)
829 plt.close(fig)
830
831
832def plot_hankel_singular_values(out_dir: Path, hsv_by_case: dict[str, np.ndarray]) -> None:
833 plt = _load_pyplot()
834 fig, ax = plt.subplots(figsize=(7.0, 4.6))
835 for case, hsv in hsv_by_case.items():
836 n = min(80, hsv.size)
837 ax.semilogy(
838 np.arange(1, n + 1),
839 hsv[:n] / max(hsv[0], 1e-300),
840 marker="o",
841 markersize=3,
842 label=case.replace("_", " "),
843 )
844 ax.set_title("Normalized block-Hankel singular values")
845 ax.set_xlabel("index")
846 ax.set_ylabel("σ_i / σ_1")
847 ax.grid(True, alpha=0.3)
848 ax.legend(fontsize=8)
849 fig.tight_layout()
850 fig.savefig(out_dir / "mimo_reduction_stress_hankel_singular_values.png", dpi=160)
851 plt.close(fig)
852
853
854def plot_pick_eigenvalues(out_dir: Path, diagnostics: dict[str, dict[str, object]]) -> None:
855 plt = _load_pyplot()
856 fig, ax = plt.subplots(figsize=(7.0, 4.6))
857 for case, diag in diagnostics.items():
858 eig = np.asarray(diag["pick_eigenvalues"], dtype=float)
859 ax.plot(np.arange(1, eig.size + 1), eig, marker="o", label=case.replace("_", " "))
860 ax.axhline(0.0, linewidth=1.0)
861 ax.set_title("Scaled tangential Pick eigenvalues")
862 ax.set_xlabel("eigenvalue index")
863 ax.set_ylabel("eigenvalue")
864 ax.grid(True, alpha=0.3)
865 ax.legend(fontsize=8)
866 fig.tight_layout()
867 fig.savefig(out_dir / "mimo_reduction_stress_pick_eigenvalues.png", dpi=160)
868 plt.close(fig)
869
870
871def plot_timing_curves(out_dir: Path, rows: list[dict[str, object]]) -> None:
872 plt = _load_pyplot()
873 cases = sorted({str(row["case"]) for row in rows})
874 fig, axes = plt.subplots(1, len(cases), figsize=(14, 4.2), sharey=False)
875 if len(cases) == 1:
876 axes = [axes]
877 for ax, case in zip(axes, cases, strict=True):
878 methods = sorted({str(row["method"]) for row in rows if row["case"] == case})
879 for method in methods:
880 sub = [row for row in rows if row["case"] == case and row["method"] == method]
881 sub = sorted(sub, key=lambda r: int(r["order"]))
882 xs = [int(r["order"]) for r in sub]
883 ys = [float(r["total_seconds"]) for r in sub]
884 ax.plot(xs, ys, marker="o", label=method.replace("_", " "))
885 ax.set_title(case.replace("_", " "))
886 ax.set_xlabel("reduced order / FIR retained blocks")
887 ax.set_ylabel("wall time (seconds)")
888 ax.grid(True, alpha=0.3)
889 axes[0].legend(loc="best", fontsize=8)
890 fig.suptitle("Reduction and reconstruction timing", y=1.04)
891 fig.tight_layout()
892 fig.savefig(out_dir / "mimo_reduction_stress_timing.png", dpi=160)
893 plt.close(fig)
894
895
896def plot_first_markov_blocks(out_dir: Path, cases: list[StressCase]) -> None:
897 plt = _load_pyplot()
898 fig, axes = plt.subplots(1, len(cases), figsize=(12.5, 3.6))
899 if len(cases) == 1:
900 axes = [axes]
901 for ax, case in zip(axes, cases, strict=True):
902 m0 = case.markov[0]
903 im = ax.imshow(m0)
904 ax.set_title(case.slug.replace("_", " "))
905 ax.set_xlabel("input")
906 ax.set_ylabel("output")
907 fig.colorbar(im, ax=ax, fraction=0.046, pad=0.04)
908 fig.suptitle("First Markov matrix M0 for each stress case", y=1.04)
909 fig.tight_layout()
910 fig.savefig(out_dir / "mimo_reduction_stress_first_markov_blocks.png", dpi=160)
911 plt.close(fig)
912
913
914def main() -> None:
915 out_dir = artifact_dir()
916 cases = build_cases()
917 all_rows: list[dict[str, object]] = []
918 hsv_by_case: dict[str, np.ndarray] = {}
919 diagnostics: dict[str, dict[str, object]] = {}
920
921 print("MIMO model-reduction stress cases", flush=True)
922 print("---------------------------------", flush=True)
923 for i, case in enumerate(cases):
924 rows, hsv, diag = evaluate_case(case, seed=880 + i)
925 all_rows.extend(rows)
926 hsv_by_case[case.slug] = hsv
927 diagnostics[case.slug] = diag
928 samples, outputs, inputs = case.markov.shape
929 finite_rows = [
930 row
931 for row in rows
932 if row["method"] == "finite_block_hankel_mimo"
933 and np.isfinite(float(row["relative_h2_error"]))
934 ]
935 best = min(finite_rows, key=lambda row: float(row["relative_h2_error"]))
936 print(f"case: {case.slug}", flush=True)
937 print(f" shape: samples={samples}, outputs={outputs}, inputs={inputs}", flush=True)
938 print(f" block Hankel: rows={case.block_rows}, cols={case.block_cols}")
939 print(
940 f" first/20th normalized HSV: 1.000e+00 / {hsv[min(19, hsv.size - 1)] / max(hsv[0], 1e-300):.3e}"
941 )
942 print(f" tangential Schur scale: {float(diag['scale']):.6g}")
943 print(f" scaled Pick min eigenvalue: {float(diag['min_pick_eigenvalue']):.3e}")
944 print(
945 " best finite block-Hankel order: "
946 f"{int(best['order'])}, relative H2 error={float(best['relative_h2_error']):.3e}, "
947 f"relative Hankel-norm error={float(best['relative_hankel_norm_error']):.3e}, "
948 f"tangential sample error={float(best['tangential_sample_error']):.3e}"
949 )
950 print(
951 " reducer timing at best order: "
952 f"reduction={float(best['reduction_seconds']):.3f}s, "
953 f"Markov expansion={float(best['expansion_seconds']):.3f}s, "
954 f"total={float(best['total_seconds']):.3f}s"
955 )
956 print(f" backend at best order: {best['backend']}")
957 if case.condition_hint is not None:
958 print(f" modal dynamic-range condition hint: {case.condition_hint:.3e}")
959
960 write_summary_csv(out_dir / "mimo_reduction_stress_summary.csv", all_rows)
961 write_case_metadata(out_dir / "mimo_reduction_stress_case_metadata.csv", cases, diagnostics)
962 plot_error_curves(out_dir, all_rows)
963 plot_hankel_singular_values(out_dir, hsv_by_case)
964 plot_pick_eigenvalues(out_dir, diagnostics)
965 plot_timing_curves(out_dir, all_rows)
966 plot_first_markov_blocks(out_dir, cases)
967
968
969if __name__ == "__main__":
970 main()