Adaptive reflection update-period sweep¶
Tutorial goal
Measure speed/quality effects of updating reflection coefficients less often.
Note
New to the terminology? See the lattice DSP concept map and the causality/data-use guide for how online, offline, block, and MIMO examples should be read.
Context¶
Adaptive IIR models can save work by updating denominator/reflection coefficients less frequently than numerator taps. The benchmark sweeps the update period and writes both JSON and CSV outputs.
Key idea and equations¶
Larger update periods reduce update count. The question is whether tail MSE remains close to the period-1 baseline.
How to read the result¶
Look for the largest period with a good speedup and modest tail-MSE degradation.
Run command¶
python benchmarks/adaptive_period_sweep.py --periods 1 2 4 8 16 --samples 12000 --repeats 3 --output docs/benchmarks/generated/_artifacts/adaptive_period_sweep/adaptive-period-sweep.json --csv-output docs/benchmarks/generated/_artifacts/adaptive_period_sweep/adaptive-period-sweep.csv
Run status¶
Return code: 0
Visual and data readout¶
When the benchmark gallery is built with results, this page embeds PNG summaries generated from the same JSON/CSV artifacts. The raw data stay available below as downloads so exact numbers remain reproducible without making the public page read like console output.
Figures¶
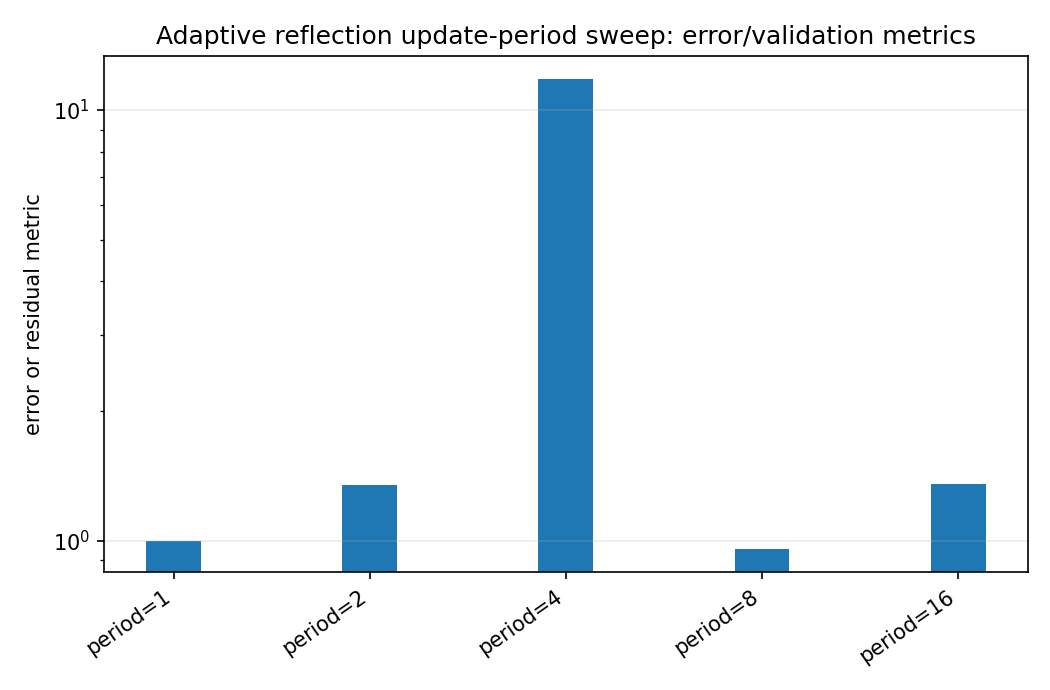
adaptive_period_sweep_error_summary.png¶
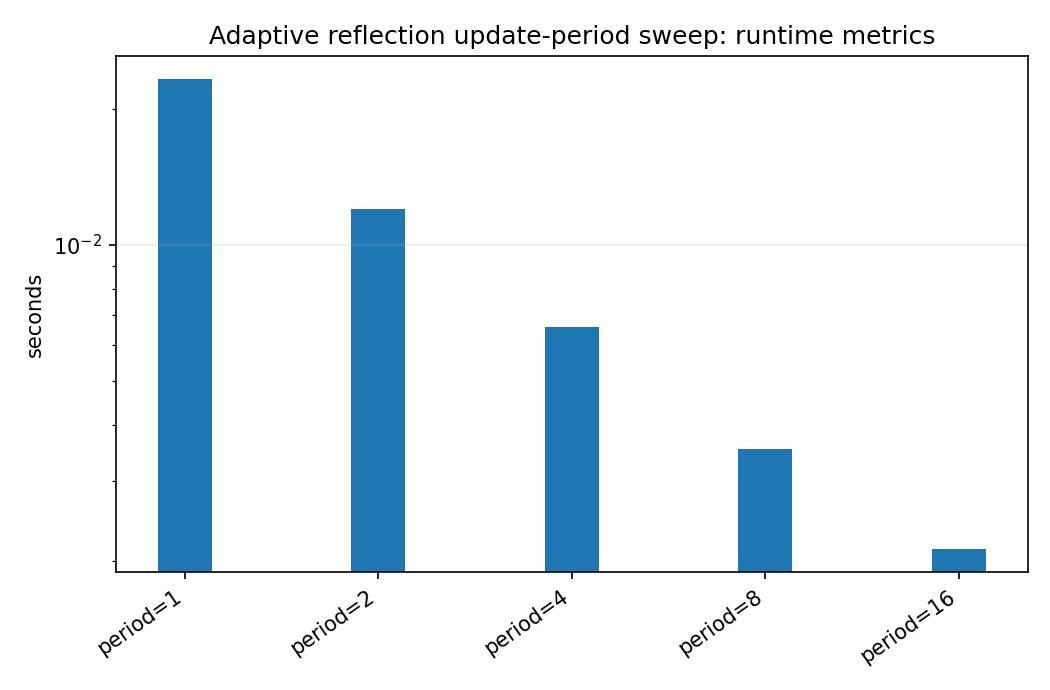
adaptive_period_sweep_runtime_summary.png¶
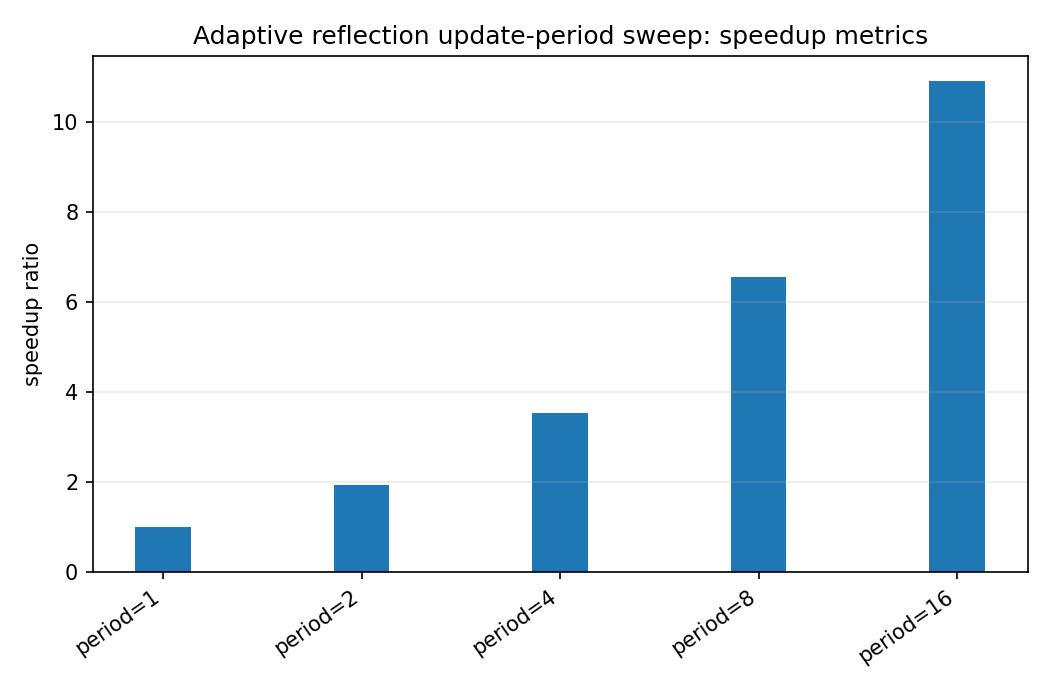
adaptive_period_sweep_speedup_summary.png¶
Generated data files¶
Source code¶
1"""Sweep adaptive reflection-update periods and record speed/quality trade-offs.
2
3The adaptive IIR update has two different costs:
4
5* numerator/ladder updates, which are cheap and can run every sample; and
6* reflection/denominator updates, which are more expensive and often noisier.
7
8By default, the script enables period-scaled reflection steps so period K uses
9``mu_reflection * K`` on update samples. This makes the speed/quality comparison
10fairer than giving long periods K-times fewer effective denominator updates.
11
12This script evaluates that trade-off by running the same identification problem
13with several ``reflection_update_period`` values. It reports runtime plus MSE
14and coefficient-error metrics, then writes JSON and optional CSV output.
15
16Example
17-------
18python benchmarks/adaptive_period_sweep.py --periods 1 2 4 8 16 32 \
19 --samples 20000 --repeats 5 --output adaptive-period-sweep.json
20"""
21
22from __future__ import annotations
23
24import argparse
25import csv
26import json
27import platform
28import statistics
29import time
30from pathlib import Path
31
32import numpy as np
33
34from lattice_dsp import AdaptiveLatticeLadderNLMS, HAS_OPENMP, LatticeIIR
35
36
37def parse_periods(values: list[str]) -> list[int]:
38 """Parse period CLI values, accepting either space- or comma-separated input."""
39 periods: list[int] = []
40 for value in values:
41 for token in value.split(","):
42 token = token.strip()
43 if not token:
44 continue
45 period = int(token)
46 if period <= 0:
47 raise ValueError("reflection update periods must be positive")
48 periods.append(period)
49 if not periods:
50 raise ValueError("at least one period is required")
51 # Preserve order while removing duplicates.
52 return list(dict.fromkeys(periods))
53
54
55def mse(x: np.ndarray) -> float:
56 return float(np.mean(np.square(x)))
57
58
59def run_trial(
60 period: int,
61 x: np.ndarray,
62 desired: np.ndarray,
63 target_reflection: np.ndarray,
64 target_taps: np.ndarray,
65 *,
66 mu_taps: float,
67 mu_reflection: float,
68 epsilon: float,
69 margin: float,
70 tail: int,
71 scale_reflection_mu_by_period: bool,
72) -> tuple[float, dict[str, float]]:
73 adaptive = AdaptiveLatticeLadderNLMS(
74 [0.0] * int(target_reflection.size),
75 [0.0] * int(target_taps.size),
76 mu_taps=mu_taps,
77 mu_reflection=mu_reflection,
78 epsilon=epsilon,
79 margin=margin,
80 freeze_reflection=False,
81 gradient_mode="analytic",
82 reflection_update_period=period,
83 scale_reflection_mu_by_period=scale_reflection_mu_by_period,
84 )
85
86 start = time.perf_counter()
87 y, err = adaptive.process_adapt(x, desired)
88 elapsed = time.perf_counter() - start
89
90 err = np.asarray(err, dtype=np.float64)
91 y = np.asarray(y, dtype=np.float64)
92 final_reflection = np.asarray(adaptive.reflection, dtype=np.float64)
93 final_taps = np.asarray(adaptive.taps, dtype=np.float64)
94 tail_n = min(tail, err.size)
95
96 quality = {
97 "mse_total": mse(err),
98 "mse_head": mse(err[:tail_n]),
99 "mse_tail": mse(err[-tail_n:]),
100 "output_power": mse(y),
101 "reflection_l2_error": float(np.linalg.norm(final_reflection - target_reflection)),
102 "taps_l2_error": float(np.linalg.norm(final_taps - target_taps)),
103 "max_abs_reflection": float(np.max(np.abs(final_reflection)))
104 if final_reflection.size
105 else 0.0,
106 "stability_margin": float(1.0 - np.max(np.abs(final_reflection)))
107 if final_reflection.size
108 else 1.0,
109 }
110 return elapsed, quality
111
112
113def sweep(args: argparse.Namespace) -> dict[str, object]:
114 periods = parse_periods(args.periods)
115 rng = np.random.default_rng(args.seed)
116 x = rng.normal(size=args.samples).astype(np.float64)
117
118 target_reflection = np.asarray(args.target_reflection, dtype=np.float64)
119 target_taps = np.asarray(args.target_taps, dtype=np.float64)
120 target = LatticeIIR(target_reflection.tolist(), target_taps.tolist())
121 desired = np.asarray(target.process(x), dtype=np.float64)
122 if args.noise_std > 0.0:
123 desired = desired + rng.normal(scale=args.noise_std, size=desired.shape)
124
125 rows: list[dict[str, object]] = []
126 baseline_median: float | None = None
127 baseline_tail_mse: float | None = None
128
129 for period in periods:
130 timings: list[float] = []
131 quality: dict[str, float] | None = None
132 for _ in range(args.repeats):
133 elapsed, quality = run_trial(
134 period,
135 x,
136 desired,
137 target_reflection,
138 target_taps,
139 mu_taps=args.mu_taps,
140 mu_reflection=args.mu_reflection,
141 epsilon=args.epsilon,
142 margin=args.margin,
143 tail=args.tail,
144 scale_reflection_mu_by_period=args.scale_reflection_mu_by_period,
145 )
146 timings.append(elapsed)
147 assert quality is not None
148 median_s = statistics.median(timings)
149 if baseline_median is None:
150 baseline_median = median_s
151 baseline_tail_mse = quality["mse_tail"]
152
153 row: dict[str, object] = {
154 "reflection_update_period": period,
155 "min_s": min(timings),
156 "median_s": median_s,
157 "max_s": max(timings),
158 "speedup_vs_first_period": (baseline_median / median_s) if median_s > 0.0 else None,
159 **quality,
160 "tail_mse_ratio_vs_first_period": (
161 quality["mse_tail"] / baseline_tail_mse
162 if baseline_tail_mse and baseline_tail_mse > 0.0
163 else None
164 ),
165 }
166 rows.append(row)
167
168 return {
169 "metadata": {
170 "python": platform.python_version(),
171 "platform": platform.platform(),
172 "has_openmp": HAS_OPENMP,
173 "samples": args.samples,
174 "repeats": args.repeats,
175 "seed": args.seed,
176 "periods": periods,
177 "mu_taps": args.mu_taps,
178 "mu_reflection": args.mu_reflection,
179 "scale_reflection_mu_by_period": args.scale_reflection_mu_by_period,
180 "epsilon": args.epsilon,
181 "margin": args.margin,
182 "noise_std": args.noise_std,
183 "tail": min(args.tail, args.samples),
184 "target_reflection": target_reflection.tolist(),
185 "target_taps": target_taps.tolist(),
186 },
187 "results": rows,
188 }
189
190
191def write_csv(path: Path, results: dict[str, object]) -> None:
192 rows = results["results"]
193 if not isinstance(rows, list) or not rows:
194 return
195 path.parent.mkdir(parents=True, exist_ok=True)
196 with path.open("w", newline="", encoding="utf-8") as f:
197 writer = csv.DictWriter(f, fieldnames=list(rows[0].keys()))
198 writer.writeheader()
199 writer.writerows(rows) # type: ignore[arg-type]
200
201
202def main() -> None:
203 parser = argparse.ArgumentParser(description=__doc__)
204 parser.add_argument("--periods", nargs="+", default=["1", "2", "4", "8", "16", "32"])
205 parser.add_argument("--samples", type=int, default=20_000)
206 parser.add_argument("--repeats", type=int, default=5)
207 parser.add_argument("--seed", type=int, default=1234)
208 parser.add_argument("--tail", type=int, default=2_000)
209 parser.add_argument("--mu-taps", type=float, default=0.05)
210 parser.add_argument("--mu-reflection", type=float, default=0.001)
211 parser.add_argument(
212 "--no-scale-reflection-mu-by-period",
213 dest="scale_reflection_mu_by_period",
214 action="store_false",
215 help="Disable period scaling and keep the same raw mu_reflection for every update period.",
216 )
217 parser.set_defaults(scale_reflection_mu_by_period=True)
218 parser.add_argument("--epsilon", type=float, default=1e-8)
219 parser.add_argument("--margin", type=float, default=1e-4)
220 parser.add_argument("--noise-std", type=float, default=0.0)
221 parser.add_argument(
222 "--target-reflection", nargs="+", type=float, default=[0.35, -0.25, 0.15, -0.08]
223 )
224 parser.add_argument(
225 "--target-taps", nargs="+", type=float, default=[0.2, -0.1, 0.05, 0.0, 0.75]
226 )
227 parser.add_argument("--output", type=Path, default=Path("reports/adaptive-period-sweep.json"))
228 parser.add_argument("--csv-output", type=Path, default=None)
229 args = parser.parse_args()
230
231 if args.samples <= 0 or args.repeats <= 0 or args.tail <= 0:
232 raise SystemExit("samples, repeats, and tail must all be positive")
233 if len(args.target_taps) != len(args.target_reflection) + 1:
234 raise SystemExit("target-taps must have length len(target-reflection) + 1")
235 if args.noise_std < 0.0:
236 raise SystemExit("noise-std must be non-negative")
237
238 results = sweep(args)
239 args.output.parent.mkdir(parents=True, exist_ok=True)
240 args.output.write_text(json.dumps(results, indent=2, sort_keys=True) + "\n", encoding="utf-8")
241 print(json.dumps(results, indent=2, sort_keys=True))
242 print(f"\nWrote {args.output}")
243 if args.csv_output is not None:
244 write_csv(args.csv_output, results)
245 print(f"Wrote {args.csv_output}")
246
247
248if __name__ == "__main__":
249 main()