Finite Hankel reduction amortization benchmark¶
Tutorial goal
Measure when a one-time finite-Hankel reduction pays off during repeated high-order IIR filtering.
Note
New to the terminology? See the lattice DSP concept map and the causality/data-use guide for how online, offline, block, and MIMO examples should be read.
Context¶
The finite-Hankel reducer is a preprocessing step. This benchmark makes the speed argument explicit by measuring reduction time, full-order filtering time, reduced-order filtering time, and the break-even number of samples per channel. It separates the method is finite-Hankel/Ho–Kalman reduction, not an exact Nehari/AAK solver.
Key idea and equations¶
The break-even sample count is estimated as
How to read the result¶
Look for high filter speedup, acceptable SNR/error, stable reduced denominators, and a break-even count that is small relative to the intended workload.
Run command¶
python benchmarks/hankel_reduction_speedup.py --full-orders 16 32 --reduced-orders 4 8 12 --channels 32 --samples 20000 --repeats 3 --n-impulse 512 --hankel-rows 64 --hankel-cols 64 --output docs/benchmarks/generated/_artifacts/hankel_reduction_speedup/hankel-reduction-speedup.json
Run status¶
Return code: 0
Visual and data readout¶
When the benchmark gallery is built with results, this page embeds PNG summaries generated from the same JSON/CSV artifacts. The raw data stay available below as downloads so exact numbers remain reproducible without making the public page read like console output.
Figures¶
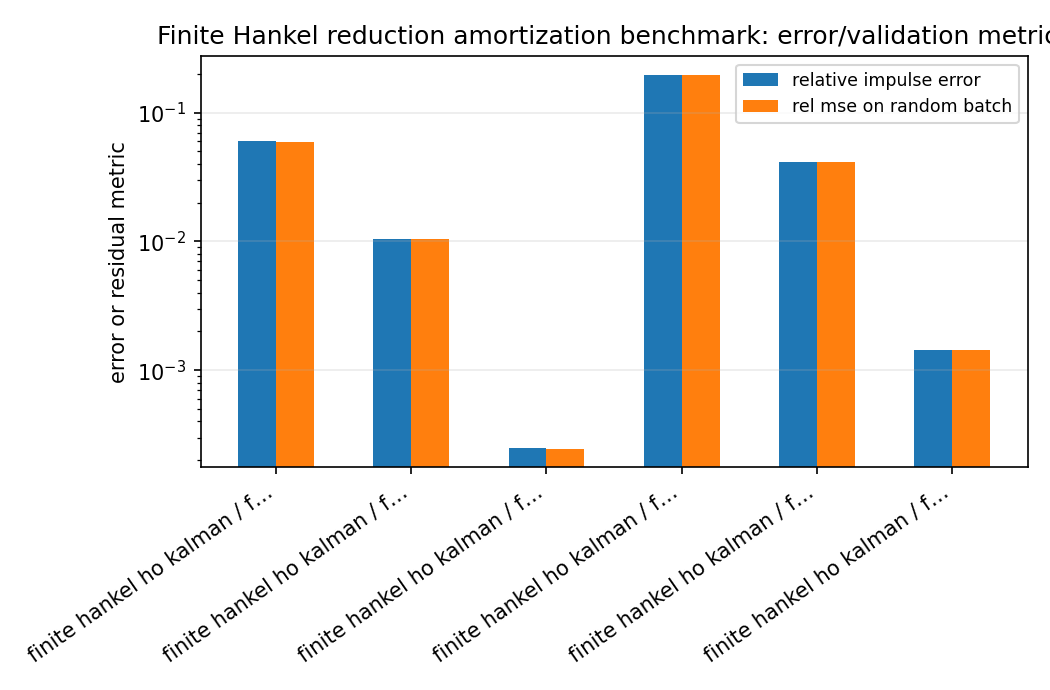
hankel_reduction_speedup_error_summary.png¶
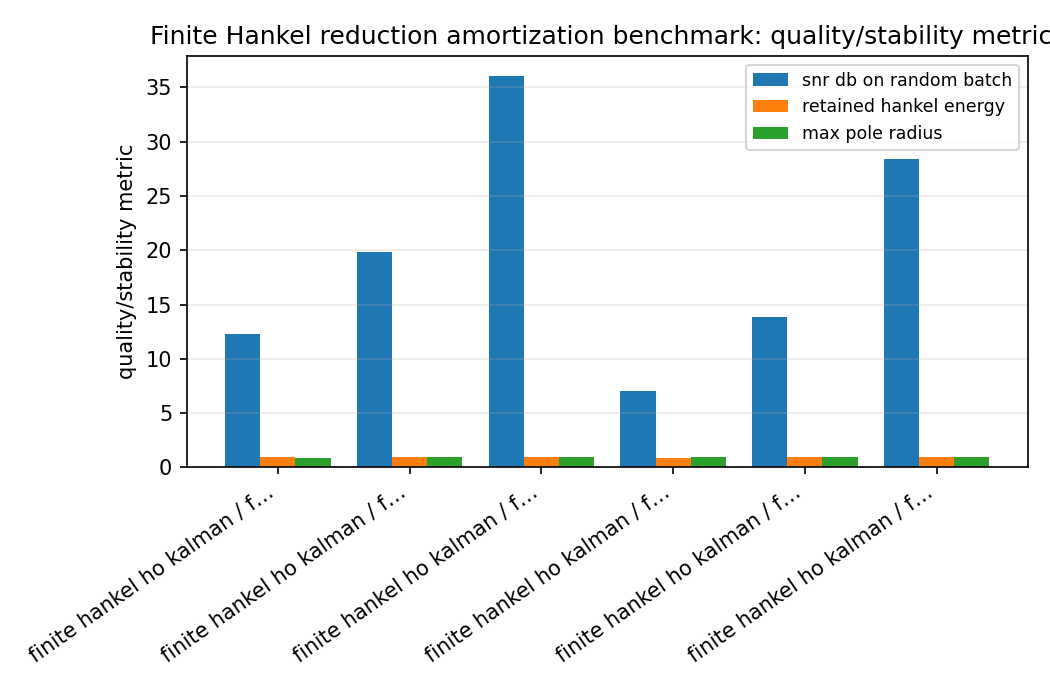
hankel_reduction_speedup_quality_summary.png¶
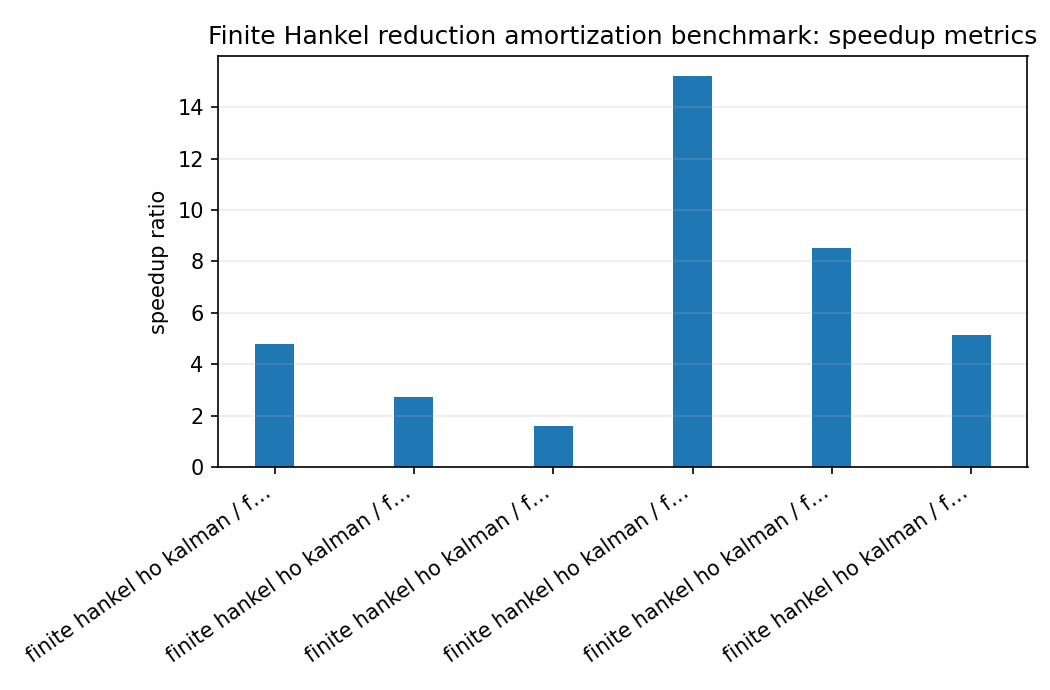
hankel_reduction_speedup_speedup_summary.png¶
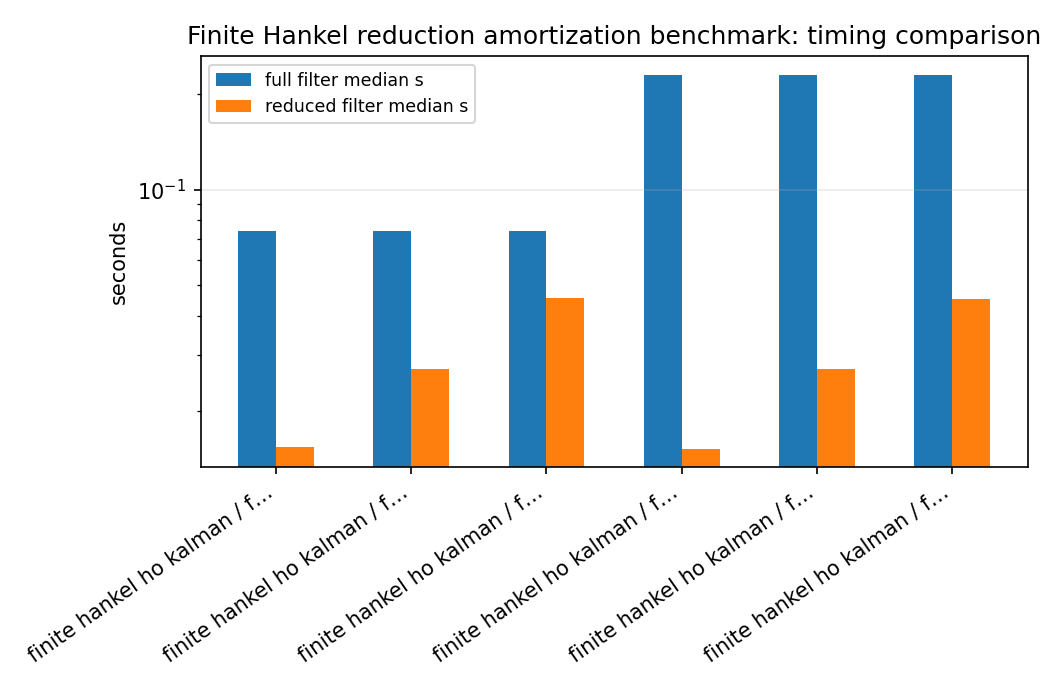
hankel_reduction_speedup_timing_comparison.png¶
Generated data files¶
Source code¶
1from __future__ import annotations
2
3import argparse
4import json
5import math
6import platform
7import statistics
8import time
9from pathlib import Path
10
11import numpy as np
12
13import lattice_dsp as ld
14
15
16def median_time(fn, repeats: int):
17 times = []
18 result = None
19 for _ in range(repeats):
20 t0 = time.perf_counter()
21 result = fn()
22 times.append(time.perf_counter() - t0)
23 return statistics.median(times), result
24
25
26def stable_reflection(order: int, rng: np.random.Generator) -> np.ndarray:
27 # Slow decay gives the reducer something nontrivial to compress while staying
28 # comfortably inside the scalar lattice stability region.
29 decay = np.exp(-np.arange(order) / max(8.0, order / 5.0))
30 signs = rng.choice([-1.0, 1.0], size=order)
31 jitter = rng.uniform(0.55, 1.0, size=order)
32 return 0.72 * decay * signs * jitter
33
34
35def numerator_for_order(order: int) -> np.ndarray:
36 n = np.zeros(order + 1, dtype=float)
37 n[0] = 1.0
38 if order >= 2:
39 n[1] = -0.18
40 n[2] = 0.08
41 if order >= 5:
42 n[4] = -0.04
43 return n
44
45
46def snr_db(reference: np.ndarray, estimate: np.ndarray) -> float:
47 err = reference - estimate
48 p_ref = float(np.mean(reference * reference))
49 p_err = float(np.mean(err * err))
50 return 10.0 * math.log10((p_ref + 1e-30) / (p_err + 1e-30))
51
52
53def pole_radius_from_reflection(reflection: list[float]) -> float:
54 if not reflection:
55 return 0.0
56 denominator = np.asarray(ld.reflection_to_denominator(reflection), dtype=float)
57 roots = np.roots(denominator)
58 return float(np.max(np.abs(roots))) if roots.size else 0.0
59
60
61def process(
62 reflection: np.ndarray | list[float], numerator: np.ndarray | list[float], x: np.ndarray
63):
64 return ld.process_batch(list(map(float, reflection)), list(map(float, numerator)), x)
65
66
67def main() -> None:
68 parser = argparse.ArgumentParser(
69 description="Benchmark finite-Hankel SISO IIR reduction amortization."
70 )
71 parser.add_argument("--full-orders", type=int, nargs="+", default=[16, 32, 64])
72 parser.add_argument("--reduced-orders", type=int, nargs="+", default=[4, 8, 12, 16])
73 parser.add_argument("--channels", type=int, default=64)
74 parser.add_argument("--samples", type=int, default=50000)
75 parser.add_argument("--repeats", type=int, default=3)
76 parser.add_argument("--n-impulse", type=int, default=768)
77 parser.add_argument("--hankel-rows", type=int, default=96)
78 parser.add_argument("--hankel-cols", type=int, default=96)
79 parser.add_argument("--seed", type=int, default=42)
80 parser.add_argument("--output", default="reports/hankel-reduction-speedup.json")
81 args = parser.parse_args()
82
83 rng = np.random.default_rng(args.seed)
84 x = rng.normal(size=(args.channels, args.samples)).astype(np.float64)
85 rows_out: list[dict[str, float | int | bool | str | None]] = []
86
87 for full_order in args.full_orders:
88 reflection = stable_reflection(full_order, rng)
89 numerator = numerator_for_order(full_order)
90
91 full_time, y_full = median_time(
92 lambda reflection=reflection, numerator=numerator: process(reflection, numerator, x),
93 args.repeats,
94 )
95 full_per_sample = full_time / (args.channels * args.samples)
96
97 for reduced_order in args.reduced_orders:
98 if reduced_order >= full_order:
99 continue
100 if reduced_order > min(args.hankel_rows, args.hankel_cols):
101 continue
102
103 reduce_time, reduced = median_time(
104 lambda ro=reduced_order, reflection=reflection, numerator=numerator: (
105 ld.finite_hankel_reduce_iir(
106 reflection.tolist(),
107 numerator.tolist(),
108 reduced_order=ro,
109 n_impulse=args.n_impulse,
110 rows=args.hankel_rows,
111 cols=args.hankel_cols,
112 )
113 ),
114 1,
115 )
116
117 if not reduced["stable"] or not reduced["reflection"]:
118 rows_out.append(
119 {
120 "full_order": full_order,
121 "reduced_order": reduced_order,
122 "stable": bool(reduced["stable"]),
123 "reduction_time_s": reduce_time,
124 "error": "reduced model was not stable in reflection coordinates",
125 }
126 )
127 continue
128
129 reduced_reflection = list(map(float, reduced["reflection"]))
130 reduced_numerator = list(map(float, reduced["numerator"]))
131 reduced_time, y_reduced = median_time(
132 lambda rr=reduced_reflection, rn=reduced_numerator: process(rr, rn, x),
133 args.repeats,
134 )
135 reduced_per_sample = reduced_time / (args.channels * args.samples)
136 delta = full_per_sample - reduced_per_sample
137 break_even_samples_per_channel = (
138 reduce_time / delta / args.channels if delta > 0 else None
139 )
140
141 rel_mse = float(np.mean((y_full - y_reduced) ** 2) / (np.mean(y_full**2) + 1e-30))
142 rows_out.append(
143 {
144 "full_order": full_order,
145 "reduced_order": reduced_order,
146 "stable": bool(reduced["stable"]),
147 "method": reduced["method"],
148 "retained_hankel_energy": float(reduced["retained_hankel_energy"]),
149 "relative_impulse_error": float(reduced["relative_impulse_error"]),
150 "rel_mse_on_random_batch": rel_mse,
151 "snr_db_on_random_batch": snr_db(y_full, y_reduced),
152 "max_pole_radius": pole_radius_from_reflection(reduced_reflection),
153 "reduction_time_s": reduce_time,
154 "full_filter_median_s": full_time,
155 "reduced_filter_median_s": reduced_time,
156 "filter_speedup": full_time / reduced_time if reduced_time > 0 else None,
157 "full_time_per_sample_s": full_per_sample,
158 "reduced_time_per_sample_s": reduced_per_sample,
159 "break_even_samples_per_channel": break_even_samples_per_channel,
160 }
161 )
162
163 result = {
164 "metadata": {
165 "python": platform.python_version(),
166 "platform": platform.platform(),
167 "has_openmp": bool(ld.HAS_OPENMP),
168 "channels": args.channels,
169 "samples": args.samples,
170 "repeats": args.repeats,
171 "n_impulse": args.n_impulse,
172 "hankel_rows": args.hankel_rows,
173 "hankel_cols": args.hankel_cols,
174 "seed": args.seed,
175 "description": "Finite-Hankel reduction amortization benchmark. Reduction is a preprocessing cost; speedup applies when the reduced model is reused.",
176 },
177 "rows": rows_out,
178 }
179
180 output = Path(args.output)
181 output.parent.mkdir(parents=True, exist_ok=True)
182 output.write_text(json.dumps(result, indent=2), encoding="utf-8")
183
184 print(json.dumps(result["metadata"], indent=2))
185 print()
186 print(
187 f"{'full':>5s} {'red':>5s} {'stable':>7s} {'reduce_s':>10s} "
188 f"{'full_s':>10s} {'red_s':>10s} {'speedup':>8s} {'SNR':>8s} {'break_even/ch':>15s}"
189 )
190 print("-" * 95)
191 for row in rows_out:
192 if "error" in row:
193 print(
194 f"{row['full_order']:5d} {row['reduced_order']:5d} {str(row['stable']):>7s} {row['reduction_time_s']:10.4f} ERROR: {row['error']}"
195 )
196 continue
197 be = row["break_even_samples_per_channel"]
198 be_text = "n/a" if be is None else f"{be:.0f}"
199 print(
200 f"{row['full_order']:5d} {row['reduced_order']:5d} {str(row['stable']):>7s} "
201 f"{row['reduction_time_s']:10.4f} {row['full_filter_median_s']:10.4f} "
202 f"{row['reduced_filter_median_s']:10.4f} {row['filter_speedup']:8.2f} "
203 f"{row['snr_db_on_random_batch']:8.2f} {be_text:>15s}"
204 )
205
206 print()
207 print(f"Wrote {output}")
208
209
210if __name__ == "__main__":
211 main()